박준일(온양여자고등학교 국어교사)
이전 글(학습과학 시리즈3: 학생이 스스로 배우고 싶게 만드는 법)에서 우리는 외적 보상의 함정에 대해 이야기했습니다. 알피 콘(Alfie Kohn)의 경고처럼, 스티커와 상품으로 학생들을 움직이면 학습이 "정말 하고 싶은 것"이 아니라 "보상을 받기 위해 억지로 해야 하는 것"으로 변질될 수 있다고요. 다니엘 핑크(Daniel Pink)의 연구도 인용하며, 당근과 채찍이 창의적인 학습에서는 오히려 역효과를 낸다고 말씀드렸습니다.
그런데 그 글을 읽고 나서 이런 질문이 떠오르셨을 수 있습니다.
"그러면 학급 칭찬 시스템은 다 없애야 하나요?"
"독서 마일리지 프로그램은 해로운 건가요?"
"스티커 한 장도 주면 안 되는 건가요?"
사실 저도 같은 고민을 했습니다. 교실에서 보상을 완전히 배제하는 것은 현실적으로 불가능에 가깝습니다. 더구나 처음부터 학습에 흥미가 없는 학생에게 "내적 동기를 가져라"고 말하는 것은 수영을 못하는 사람에게 "일단 물에 뛰어들어라"고 말하는 것과 다르지 않습니다.
이번 시리즈에서는 한 발 더 나아가 질문을 바꿔보겠습니다. 외적 보상은 정말 언제나 해로운가? 조건에 따라 내적 동기의 '마중물'이 될 수 있는가? 50년간 축적된 연구들을 꼼꼼히 살펴보면, 답은 생각보다 복잡하고, 그래서 더 희망적입니다.
외적 보상이 내적 동기를 손상시킨다는 주장의 출발점은 1973년 스탠퍼드대학교에서 수행된 유명한 실험입니다. 심리학자 마크 레퍼(Mark Lepper), 데이비드 그린(David Greene), 리처드 니스벳(Richard Nisbett)은 유치원 아이들을 대상으로 간단하면서도 강력한 실험을 설계했습니다.
연구진은 먼저 자유놀이 시간에 아이들을 관찰하여 매직펜으로 그림 그리기를 원래부터 좋아하는 아이들을 선별했습니다. 그리고 이 아이들을 세 집단으로 나누었습니다.
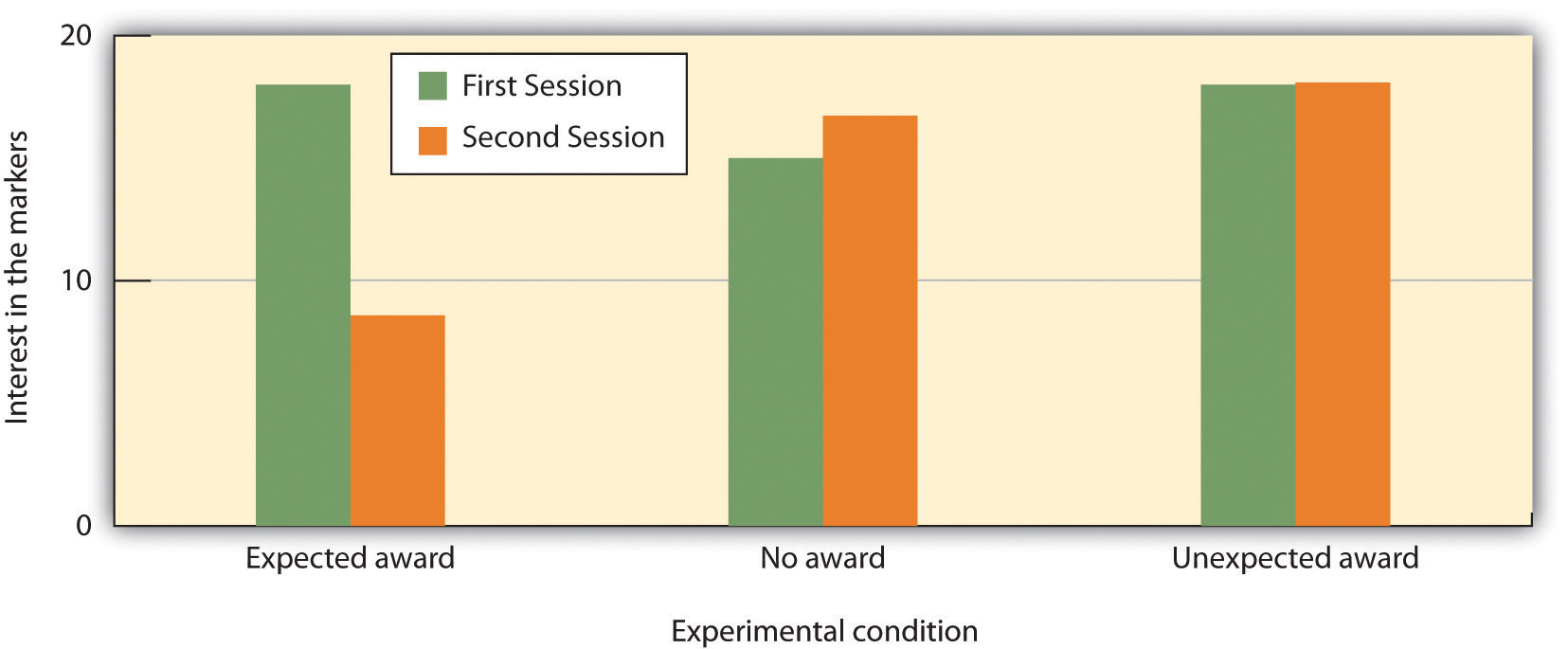
| 집단 | 조건 | 내용 |
|---|---|---|
| 예상 보상 집단 | 보상을 미리 약속 | "예쁜 그림을 그리면 '착한 어린이상'을 줄게" |
| 예상치 못한 보상 집단 | 사후에 보상 제공 | 그림을 그린 후 갑자기 "잘했어! 여기 상이야" |
| 무보상 집단 | 보상 없음 | 그냥 그림 그리기 |
2주 후, 연구진은 다시 자유놀이 시간에 아이들을 관찰했습니다. 결과는 충격적이었습니다. 예상 보상 집단의 아이들은 매직펜으로 그림 그리는 시간이 절반 이하로 급감했습니다. 반면 예상치 못한 보상 집단과 무보상 집단은 여전히 그림 그리기를 즐겼습니다.
왜 이런 일이 벌어진 걸까요? 레퍼와 동료들은 이를 과잉정당화 효과(Overjustification Effect)라고 명명했습니다. 아이들의 머릿속에서 이런 인지적 재해석이 일어난 것입니다.
"내가 그림을 그리는 이유가 뭐지? 아, 상을 받으려고 그랬구나. 상이 없으면 굳이 할 필요가 없겠네."
원래 "재미있어서" 하던 활동이 "보상을 받기 위해서" 하는 활동으로 바뀌어 버린 것입니다. 심리학에서는 이를 '귀인(歸因)의 전환'이라고 합니다. 행동의 원인을 내부(흥미, 즐거움)에서 외부(보상, 처벌)로 돌리게 되면, 외부 원인이 사라졌을 때 행동도 함께 사라집니다.
이 연구는 교육계에 큰 파장을 일으켰습니다. 레퍼 등(1973)은 논문에서 이렇게 경고했습니다. "외적 보상을 제시하는 것은 학교 교육 시스템의 핵심적인 문제를 야기할 수 있다. 아이가 학교에 처음 들어올 때 가지고 있던 학습과 탐구에 대한 내재적 흥미를 보존하는 데 실패하게 만들기 때문이다."
레퍼의 매직펜 실험 이후 25년간 수백 개의 후속 연구가 쏟아졌습니다. 결과는 엇갈렸습니다. 어떤 연구는 보상의 해로운 효과를 확인했고, 어떤 연구는 효과가 없다고 했으며, 또 어떤 연구는 오히려 긍정적 효과를 보고했습니다.
이 혼란을 정리하기 위해 1999년, 로체스터대학교의 에드워드 데시(Edward Deci), 리처드 코에스트너(Richard Koestner), 리처드 라이언(Richard Ryan)은 기념비적인 메타분석을 수행했습니다. 무려 128개의 실험 연구를 종합 분석한 것입니다.
데시 등(1999)의 메타분석 결과는 보상의 유형에 따라 효과가 크게 다르다는 것을 보여주었습니다.
| 보상 유형 | 효과 크기(d) | 해석 |
|---|---|---|
| 참여-조건부 보상 (과제에 참여하면 보상) | -0.40 | 내적 동기 감소 |
| 완료-조건부 보상 (과제를 끝내면 보상) | -0.36 | 내적 동기 감소 |
| 성과-조건부 보상 (잘하면 보상) | -0.28 | 내적 동기 감소 |
주: 효과 크기 d는 0.2가 작은 효과, 0.5가 중간 효과, 0.8이 큰 효과로 해석됨
이 결과에서 주목해야 할 점이 두 가지 있습니다.
첫째, 모든 보상이 해로운 것은 아닙니다. 언어적 보상, 즉 칭찬과 긍정적 피드백은 오히려 내적 동기를 높였습니다(d=+0.33). 이는 중간 정도의 긍정적 효과입니다. "잘했어", "이 방법이 효과적이었어"와 같은 말이 스티커나 상품권보다 더 강력한 동기 부여 도구가 될 수 있다는 뜻입니다.
둘째, 예상치 못한 보상은 해롭지 않습니다. 레퍼의 실험에서도 확인되었듯이, 사전에 약속하지 않고 사후에 주는 보상은 내적 동기에 영향을 미치지 않았습니다(d=+0.01, 사실상 제로). 과잉정당화 효과가 발생하려면 "이 행동을 하면 저 보상을 받는다"는 인과적 연결이 머릿속에 형성되어야 하는데, 예상치 못한 보상은 이 연결이 만들어지지 않기 때문입니다.
데시 등(1999)의 메타분석에서 특히 우려되는 발견이 있었습니다. 유형 보상(tangible rewards)의 부정적 효과가 성인보다 아동에게 더 크게 나타났다는 것입니다.
연구자들은 이를 인지적 발달 차이로 설명합니다. 성인은 보상의 '정보적 측면'(내가 잘하고 있다는 신호)과 '통제적 측면'(누군가 나를 조종하려 한다는 느낌)을 분리해서 해석할 수 있습니다. 하지만 아이들은 이 두 측면을 구분하는 인지적 능력이 아직 발달 중이라, 보상을 주로 '통제'로 받아들이기 쉽습니다.
데시 등(2001)은 후속 논문에서 이렇게 경고합니다. "유형 보상—피자 파티나 '착한 학생상' 같은 물질적·상징적 보상—은 많은 교육자들이 널리 옹호하고 많은 교실에서 사용되지만, 증거는 이러한 보상이 보상받는 활동에 대한 내적 동기를 손상시키는 경향이 있음을 시사한다."
여기까지 읽으면 "그러면 보상은 정말 다 나쁜 거 아닌가?"라는 생각이 들 수 있습니다. 하지만 연구를 더 깊이 들여다보면, 외적 보상이 내적 동기의 마중물로 작용할 수 있는 조건들이 명확하게 드러납니다.
데시 등(1999)의 메타분석에 대한 반론으로, 캐머런(Judy Cameron)과 동료들(2001)은 중요한 지적을 했습니다. 기존 연구들은 대부분 원래부터 흥미로운 과제를 사용했다는 것입니다. 레퍼의 매직펜 실험도 "원래 그림 그리기를 좋아하는 아이들"을 대상으로 했습니다.
캐머런 등(2001)이 저흥미 과제를 포함한 연구들을 분석한 결과, 초기 흥미가 낮은 과제에서는 보상이 오히려 내적 동기를 향상시켰습니다. 논리는 간단합니다. 밀려날(crowd out) 동기 자체가 없으면, 밀려날 것도 없습니다.
교실에서 생각해 봅시다. 한자 쓰기, 영어 단어 암기, 수학 연산 연습과 같은 반복 학습들은 학생들이 처음부터 흥미를 느끼기 어려워할 수 있습니다.. 이런 과제에 대해서는 전략적으로 외적 보상을 활용하는 것이 오히려 효과적일 수 있습니다.
앞서 살펴보았듯이, 모든 메타분석에서 언어적 보상은 일관되게 내적 동기를 향상시켰습니다. 데시 등(1999)은 d=+0.33, 자기보고 흥미에서는 d=+0.31의 효과 크기를 보고했습니다. 캐머런과 피어스(1994)의 메타분석에서도 언어적 칭찬은 긍정적 효과를 보였습니다.
왜 언어적 보상은 다를까요? 자기결정이론(Self-Determination Theory)에 따르면, 언어적 칭찬은 유능감(competence)을 높이는 정보로 기능하기 때문입니다. "네가 잘하고 있어"라는 메시지가 전달되면, 학생은 자신의 능력에 대한 확신을 갖게 되고, 이것이 내적 동기로 연결됩니다.
단, 여기서 중요한 조건이 있습니다. 언어적 보상이 통제적(controlling)으로 느껴지면 효과가 사라지거나 역전됩니다. "내가 시킨 대로 잘했네"와 "네가 선택한 방법이 효과적이었어"는 같은 칭찬이 아닙니다.
레퍼 등(1973)의 원래 실험에서 이미 확인된 사실입니다. 예상치 못한 보상을 받은 집단은 내적 동기에 변화가 없었습니다(d≈0). 데시 등(1999)의 메타분석에서도 동일한 결과가 나왔습니다.
이유는 과잉정당화 효과의 메커니즘에 있습니다. "이 행동을 하면 → 저 보상을 받는다"는 인과적 연결이 머릿속에 형성되어야 "내가 이걸 보상 때문에 하는구나"라는 재해석이 일어납니다. 예상치 못한 보상은 이 인과 연결이 형성되지 않습니다.
교실 적용은 간단합니다. "이번 달 독서왕에게 상품권을 줄게"보다 "오늘 네가 책 읽는 모습이 정말 몰입해 보여서 선생님이 감동받았어. 이거 받아"가 더 효과적입니다.
라이언과 데시(2020)는 자기결정이론의 최신 종합 논문에서, 자율성 지지(autonomy support)와 구조(structure)가 함께 제공될 때 외적 동기의 내재화가 촉진된다고 보고했습니다.
자율성 지지란 무엇일까요?
| 자율성 지지 요소 | 설명 | 교실 예시 |
|---|---|---|
| 선택권 제공 | 무엇을, 어떻게, 언제 할지 선택할 수 있게 함 | "세 가지 과제 중 하나를 골라봐" |
| 이유 설명 | 왜 이것을 해야 하는지 의미를 설명 | "이 활동이 네 미래에 어떻게 도움이 될지 생각해보자" |
| 감정 인정 | 학생의 부정적 감정도 수용 | "지루하게 느껴질 수 있어. 그래도 한번 해볼까?" |
보상이 이러한 자율성 지지 환경에서 제공되면, 학생은 보상을 '통제'가 아닌 '정보'로 해석할 가능성이 높아집니다.
울리(Kaitlin Woolley)와 피쉬바흐(Ayelet Fishbach)는 2018년 Journal of Personality and Social Psychology에 발표한 연구에서 흥미로운 발견을 했습니다. 즉각적 보상이 지연된 보상보다 내적 동기를 유의미하게 향상시킨다는 것입니다.
연구진은 여러 실험을 통해, 과제 수행 직후 즉시 보상을 받은 참가자들이 나중에 보상을 받은 참가자들보다 해당 활동에 대한 내적 흥미가 더 높아졌음을 확인했습니다. 2022년 후속 연구에서도 이 결과가 재확인되었습니다.
이유는 시간적 근접성에 있습니다. 보상이 즉각적으로 주어지면, 보상과 활동 자체의 즐거움이 연결됩니다. 반면 보상이 지연되면, 보상은 활동과 분리된 별개의 것으로 인식됩니다.
| 조건 | 핵심 연구 | 핵심 원리 |
|---|---|---|
| ① 초기 흥미가 낮은 과제 | Cameron 등(2001) | 밀려날 동기가 없으면 밀려나지 않음 |
| ② 언어적/정보적 보상 | Deci 등(1999) | 유능감 정보로 기능 |
| ③ 예상치 못한 보상 | Lepper 등(1973) | 인과 연결 미형성 |
여기서 더 근본적인 질문을 던져봅시다. 외적 동기와 내적 동기는 완전히 별개의 것일까요? 아니면 연결될 수 있을까요?
데시와 라이언의 자기결정이론(Self-Determination Theory)은 동기를 이분법이 아닌 연속체(continuum)로 봅니다.
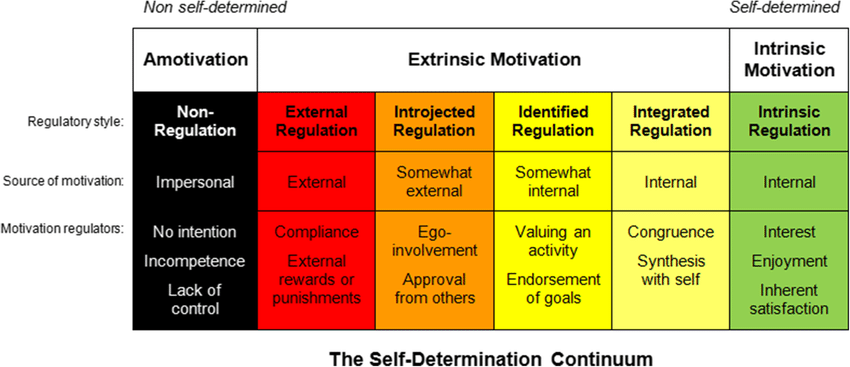
이 모델에서 핵심은 외적 동기가 점진적으로 내재화(internalization)될 수 있다는 것입니다.
| 조절 유형 | 특징 | 학생의 예시 발화 |
|---|---|---|
| 외적 조절 | 보상 획득/처벌 회피 | "선생님한테 혼나기 싫어서 숙제해요" |
| 내사적 조절 | 죄책감, 자존심 | "숙제 안 하면 찝찝해서..." |
| 동일시 조절 | 개인적 중요성 인식 | "영어 잘하면 나중에 도움이 되니까요" |
라이언과 데시(2020)에 따르면, 이 내재화 과정은 세 가지 기본 심리 욕구가 충족될 때 촉진됩니다.
2024년, 바다크(Lisa Bardach)와 무라야마(Kou Murayama)는 Learning and Instruction 저널에 발표한 리뷰 논문에서 보상-학습 프레임워크(reward-learning framework)를 제안하며 '동기 전환(motivation transformation)'이라는 개념을 구체화했습니다.
핵심 통찰은 이것입니다.
"외적 보상은 참여의 '진입점(entry point)'으로 작용하여, 학생들이 내적으로 보람 있는 학습 과정의 긍정적 피드백 루프를 시작하도록 도울 수 있다."
이를 경로로 표현하면 다음과 같습니다.
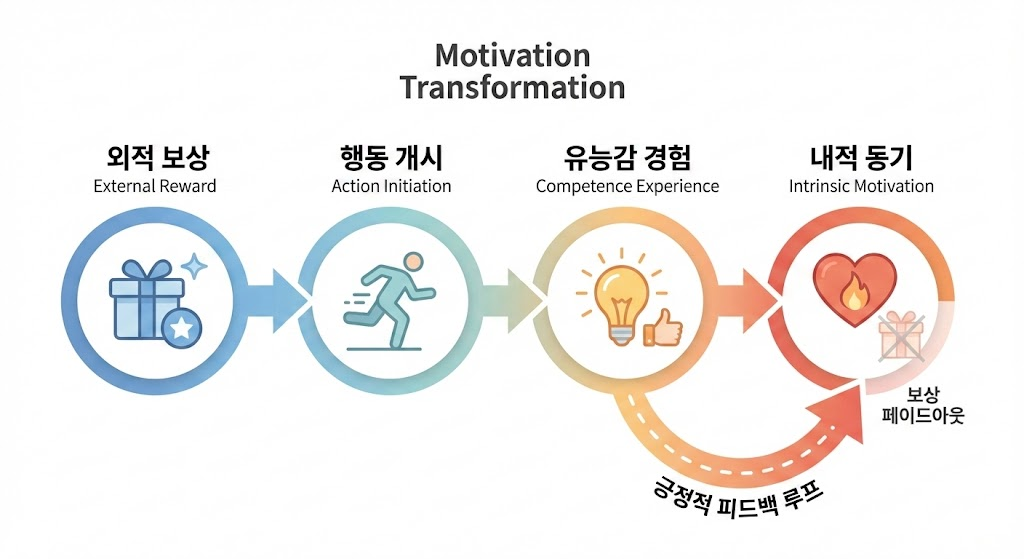
쉽게 말해, 처음에는 스티커나 칭찬 때문에 시작했더라도, 그 과정에서 "어, 나 이거 할 수 있네?"라는 유능감을 경험하고, "생각보다 재미있네?"라는 내적 보상을 발견하면, 더 이상 외적 보상이 없어도 스스로 하고 싶어진다는 것입니다.
하지만 연구자들은 중요한 경고도 덧붙입니다.
"일단 이러한 긍정적 피드백 루프가 확립되면, 외적 인센티브는 그 과정을 방해하여 잠재적으로 장기적 참여를 훼손할 수 있다."
이것이 바로 마중물의 지혜입니다. 펌프에서 물을 끌어올리려면 처음에 마중물이 필요하지만, 물이 올라오기 시작하면 마중물을 계속 부을 필요가 없습니다. 더 나아가, 물이 잘 오르는데도 마중물을 계속 부으면 오히려 물이 넘쳐 펌프가 고장 날 수 있습니다.
리(Li) 등(2023)은 교육에서의 게이미피케이션(gamification) 효과를 자기결정이론 관점에서 메타분석했습니다. 게이미피케이션이란 게임 요소(점수, 배지, 리더보드, 도전 과제 등)를 교육에 적용하는 것을 말합니다.
결과는 흥미로웠습니다.
| 결과 변인 | 효과 크기(g) | 해석 |
|---|---|---|
| 내적 동기 | +0.305 | 작은~중간 정도의 긍정적 효과 |
| 자율성 | +0.638 | 중간 정도의 긍정적 효과 |
| 관계성 | +1.776 | 큰 긍정적 효과 |
게이미피케이션은 외적 보상 시스템임에도 불구하고 내적 동기를 향상시켰습니다. 연구자들은 이를 SDT 관점에서 이렇게 해석합니다. "외적 동기는 내재화됨에 따라 내적 동기로 이동할 수 있다."
특히 관계성(g=+1.776)의 효과가 두드러지는데, 이는 게이미피케이션이 종종 협동 요소나 사회적 비교를 포함하기 때문입니다. 교실에서 보상 시스템을 설계할 때, 단순히 개인에게 보상을 주는 것보다 모둠 활동이나 협력적 요소와 연결하는 것이 효과적일 수 있음을 시사합니다.
이제 연구 결과들을 교실 실천으로 가져와 봅시다. 다섯 가지 전략을 제안합니다.
스탠퍼드대학교의 캐롤 드웩(Carol Dweck)과 뮬러(Claudia Mueller)는 1998년 Journal of Personality and Social Psychology에 발표한 연구에서, 칭찬의 내용이 학생의 후속 동기와 행동에 결정적 영향을 미친다는 것을 보여주었습니다.
연구진은 5학년 학생들에게 문제를 풀게 한 후, 세 집단으로 나누어 다른 유형의 칭찬을 했습니다.
| 칭찬 유형 | 예시 | 후속 행동 |
|---|---|---|
| 인물 칭찬 (능력 귀인) | "정말 똑똑하구나!" | 쉬운 과제 선택, 실패 후 포기 |
| 과정 칭찬 (노력 귀인) | "정말 열심히 했구나!" | 도전적 과제 선택, 실패 후 지속 |
| 무칭찬 (통제 집단) | (결과만 알려줌) | 중간 수준 |
결과는 놀라웠습니다. 인물 칭찬을 받은 학생들은 더 쉬운 과제를 선택했고, 어려운 문제에서 실패하면 쉽게 포기했습니다. 반면 과정 칭찬을 받은 학생들은 더 도전적인 과제를 선택했고, 실패해도 계속 시도했습니다.
왜 이런 차이가 날까요? 인물 칭찬("넌 똑똑해")을 받으면, 학생은 자신의 정체성을 '똑똑한 사람'으로 규정합니다. 그러면 어려운 문제에 도전해서 실패하는 것은 "나는 사실 똑똑하지 않다"는 위협이 됩니다. 그래서 위험을 피하려 합니다.
반면 과정 칭찬("열심히 했구나")을 받으면, 학생은 성공의 원인을 '노력'으로 귀인합니다. 노력은 통제 가능한 것이므로, 실패해도 "더 노력하면 된다"고 생각합니다.
교실에서의 적용 예시
| 인물 칭찬 (피하기) | 과정 칭찬 (권장) |
|---|---|
| "역시 넌 글을 잘 써!" | "인물의 심리를 구체적으로 묘사한 부분이 독자의 마음을 움직이겠어" |
| "수학 천재야!" | "어려운 문제에서 포기하지 않고 세 번이나 다시 풀어본 게 대단해" |
| "발표 잘했어, 타고났어!" | "긴장되었을 텐데 끝까지 또박또박 말한 게 인상적이야" |
| "영어 센스가 있네!" | "모르는 단어를 문맥으로 유추한 전략이 효과적이었어" |
핵심은 구체적이고 정보적인 피드백입니다. "잘했어"는 별로 도움이 되지 않습니다. 무엇을, 어떻게 잘했는지를 짚어주어야 학생이 "아, 이렇게 하면 되는구나"라는 유능감을 얻습니다.
레퍼 등(1973)과 데시 등(1999)의 연구가 일관되게 보여주듯, 예상된 보상이 문제입니다. "이번 달 독서왕에게 상품권!"은 전형적인 예상 보상입니다.
대안은 예상치 못한 인정입니다.
| 예상 보상 (피하기) | 예상치 못한 인정 (권장) |
|---|---|
| "발표 잘하면 가산점 줄게" | (발표 후) "오늘 네 발표가 정말 인상적이었어. 선생님이 감동받았어" |
| "숙제 100% 제출하면 피자 파티" | (어느 날 갑자기) "여러분이 한 달 동안 열심히 한 모습이 보기 좋아서 오늘 간식 준비했어" |
| "독서 50권 달성하면 문화상품권" | (책 읽는 모습을 보고) "오늘 네가 책에 빠져 있는 모습이 정말 멋졌어" |
캐머런 등(2001)의 연구에서 확인되었듯이, 초기 흥미가 낮은 과제에서는 보상이 효과적일 수 있습니다. 핵심은 보상을 시작점으로 사용하되, 내적 동기가 싹트면 점진적으로 페이드아웃하는 것입니다.
한자/영단어 암기 과제 예시
| 단계 | 목표 | 전략 |
|---|---|---|
| 초기 (진입) | 일단 시작하게 만들기 | 마일리지 시스템: "50개 외우면 스티커" |
| 중기 (유능감) | 잘하고 있다는 느낌 주기 | 전략 피드백: "오늘 연상법 쓴 거 효과적이었어. 기억이 더 오래 갈 거야" |
| 후기 (내재화) | 스스로 목표 설정하게 하기 | 보상 페이드아웃: "이번 주는 네가 목표를 정해봐. 몇 개 도전해볼까?" |
코르도바(Diana Cordova)와 레퍼(1996)는 학생들에게 선택권을 주는 것만으로도 내적 동기와 학습 성과가 모두 향상된다는 것을 발견했습니다.
자율성 지지의 구체적 방법:
| 영역 | 선택권 부여 예시 |
|---|---|
| 무엇을 할지 | "세 가지 주제 중 하나를 골라서 글을 써봐" |
| 어떻게 할지 | "발표, 포스터, 영상 중 원하는 방식으로 결과물을 만들어봐" |
| 누구와 할지 | "혼자 할지, 짝과 할지, 모둠으로 할지 정해봐" |
| 언제 할지 | "이번 주 안에 제출하면 돼. 언제 할지는 네가 정해" |
울리와 피쉬바흐(2018)의 연구에서 확인되었듯이, 보상의 시점도 중요합니다. 즉각적 피드백이 지연된 피드백보다 내적 동기를 더 높입니다.
| 지연 피드백 (덜 효과적) | 즉각 피드백 (더 효과적) |
|---|---|
| 일주일 후 시험지 반환하며 코멘트 | 문제 풀자마자 바로 정답 확인 및 설명 |
| 학기말 성적표 코멘트 | 수업 중 즉시 "그 방법 좋아!" |
| 수행평가 결과 2주 후 공개 | 발표 직후 구체적 피드백 |
디지털 기술을 활용하면 즉각적 피드백이 더 쉬워집니다. 퀴즈 앱, 학습 관리 시스템, 실시간 응답 시스템 등을 활용해 학생들이 자신의 수행에 대한 피드백을 즉시 받을 수 있게 하세요.
많은 학교에서 독서 마일리지 프로그램을 운영합니다. "100권 읽으면 상품권"이 전형적인 형태입니다. 연구 결과를 바탕으로 재설계해 봅시다.
| 기존 방식 | 문제점 | 개선 방식 |
|---|---|---|
| "100권 읽으면 상품권" | 예상 보상, 통제적, 양 중심 | ↓ |
| "네가 고른 책에서 인상 깊은 문장 하나를 친구에게 소개해줘" (자율성, 관계성) | ||
| 소개 후: "네가 그 문장을 고른 이유가 흥미로워. 어떤 점이 마음에 와닿았어?" (정보적 피드백) | ||
학급 긍정 행동 지원(PBIS) 시스템을 많이 사용합니다. 연구 결과를 바탕으로 조정해 봅시다.
| 기존 방식 | 문제점 | 개선 방식 |
|---|---|---|
| "조용한 모둠에 스티커" | 통제적, 행동 통제 목적 | ↓ |
| "오늘 토론에서 반대 의견도 존중하며 들었던 점이 인상적이야" (정보적) | ||
| "서로 다른 생각을 나누면서 더 깊이 이해하게 됐지?" (의미 연결) |
| 기존 방식 | 문제점 | 개선 방식 |
|---|---|---|
| "발표 잘하면 보상 스티커" | 예상 보상, 성과 중심 | ↓ |
| (발표 후) "긴장되는 상황에서도 끝까지 자기 생각을 말한 용기가 대단해" (과정 칭찬) |
수행평가에서 학생들이 "점수 때문에" 억지로 하는 경우가 많습니다.
동기 내재화를 위한 수행평가 설계
| 요소 | 기존 방식 | 개선 방식 |
|---|---|---|
| 자율성 | 주제, 형식 고정 | 여러 주제/형식 중 선택 |
| 유능감 | 최종 결과만 평가 | 중간 피드백 제공, 수정 기회 |
| 관계성 | 개인 과제 | 협력 요소 포함, 동료 피드백 |
리 등(2023)의 게이미피케이션 메타분석에서 관계성 효과가 가장 컸습니다(g=+1.776). 보상을 개인이 아닌 모둠에 연결하면 관계성 욕구가 충족됩니다.
| 개인 보상 (덜 효과적) | 모둠 연결 보상 (더 효과적) |
|---|---|
| "가장 잘한 학생에게 상품" | "모둠원 모두가 목표 달성하면 함께 축하" |
| "1등에게 가산점" | "우리 모둠이 함께 성장한 점을 나눠봅시다" |
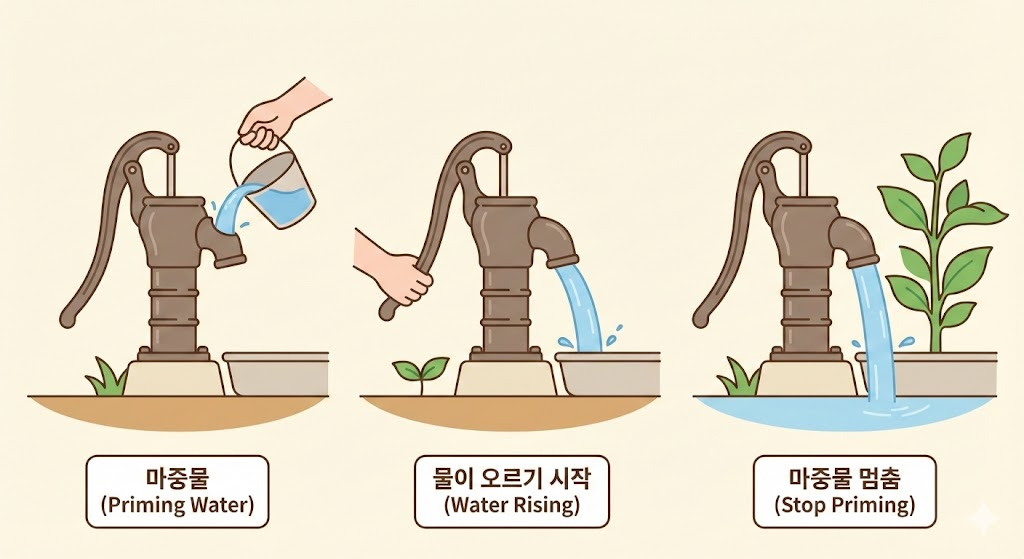
시골에서 펌프로 물을 길어본 경험이 있으신가요? 펌프가 마른 상태에서는 손잡이를 아무리 눌러도 물이 나오지 않습니다. 이때 필요한 것이 마중물입니다. 위에서 물을 조금 부어주면, 그 물이 펌프 안의 공기를 밀어내고 진공 상태를 만들어 지하수를 끌어올립니다.
외적 보상은 학습에서 마중물과 같은 역할을 할 수 있습니다.
처음에 학습에 전혀 흥미가 없는 학생에게 "내적 동기를 가져라"고 말하는 것은 마른 펌프에서 물을 기대하는 것과 같습니다. 이때 전략적인 외적 보상은 학습의 진입점이 될 수 있습니다. 스티커든, 칭찬이든, 게임 요소든—처음에 뭔가가 학생을 움직이게 해야 합니다.
그러나 마중물의 지혜는 여기서 끝나지 않습니다.
물이 올라오기 시작하면 마중물을 멈춰야 합니다. 학생이 활동 자체에서 재미를 느끼기 시작하면, 유능감을 경험하기 시작하면, "이거 생각보다 괜찮은데?"라고 말하기 시작하면—그때부터 외적 보상은 점진적으로 물러나야 합니다.
더 나아가, 물이 잘 오르는데도 마중물을 계속 부으면 펌프가 고장 납니다. 이미 학습을 즐기고 있는 학생에게 "잘하면 상 줄게"라고 하면, 바다크와 무라야마(2024)의 경고처럼 "긍정적 피드백 루프를 방해"하게 됩니다. 레퍼의 매직펜 아이들처럼, 원래 좋아하던 활동마저 "보상 때문에 하는 것"으로 변질될 수 있습니다.
결론적으로, "보상을 쓸까 말까?"는 잘못된 질문입니다. 더 정확한 질문은 이것입니다.
"어떤 보상을, 언제, 어떻게 쓰고, 언제 멈출 것인가?"
50년간의 연구가 말해주는 답은 명확합니다.
보상은 도구입니다. 망치가 좋은 도구인지 나쁜 도구인지는 망치 자체가 아니라 어떻게 쓰느냐에 달려 있듯이, 외적 보상도 마찬가지입니다. 연구에 기반한 지혜로운 사용이 학생들의 학습 동기를 끌어올리는 마중물이 될 수 있기를 바랍니다.

박준일
살아가는 힘을 기르는 교실을 만들기 위해 동료 선생님들과 함께 연대하고 싶은 교사입니다.
댓글을 작성하려면 로그인이 필요합니다.
| +0.01 |
| 효과 없음 |
| 언어적 보상 (칭찬, 긍정적 피드백) | +0.33 | 내적 동기 증가 |
| "해야 해", "~하렴" 대신 선택의 언어 사용 |
| "~해볼 수 있어", "~하는 건 어때?" |
| Ryan & Deci(2020) |
| 통제가 아닌 정보로 해석 |
| ⑤ 즉각적 제공 | Woolley & Fishbach(2018) | 활동과 보상의 연결 강화 |
| 자기 가치관과 통합 |
| "배우는 게 제 삶의 일부예요" |
| 내적 동기 | 순수한 흥미와 즐거움 | "이거 진짜 재미있어요!" |
| (예상치 못하게) "오늘 네 책 소개가 정말 좋았어. 다른 친구들도 그 책 읽고 싶어 했어" (예상치 못한 인정) |
| "이건 시험이야" |
| "이 활동이 너의 ~에 어떤 도움이 될까?" |